因为我们要重构公司现有的搜索,考虑在前的肯定是架构层面优先,比如可靠性,扩展性,所以本系列文章会优先描述架构层面的内容,至于使用后续可以慢慢探究。
本系列文章之间可能会有重复赘述的内容,也是为了更好的表述清楚关联关系。
前面介绍了集群,索引,类型等相关的内容,本文继续探讨集群,索引相关的内容。
再议分片
创建索引的时候需要指定分片数量及副本数量,默认5个分片,1套副本,总计10个分片,5个主分片,5个复制分片。
那么分片到底是怎么回事呢?分片在节点间是如何分配的呢?
举个生活中的例子来解释一下分片吧。
X市有一个牛逼的中学M, 今年有3600个考生考入了M, 我们不可能将3600个考生都扔到一个教室里吧,况且教室也不够大呀,所以经过校长会议讨论,决定开设36个班级,计划每班100个学生(人数多吗?我上学的时候还是少的呢,谁让我们是河南考生)。
现在问题来了:考生如何分班?会议上大家讨论很激烈,有说按姓名笔画来分的,有说按高低个来分的,有说按性别来分的,最终教务处主任拍案选定了按成绩取余的方式进行,用每个考生的成绩除以36,余1分到1班,余2分到2班,以此类推,余0分到36班,这样很快就分好了,每个班的学生成绩分布相对比较均衡(有好有差嘛,也不一定,理想情况下差不多)。
开学了,大家有序进入各自的教室开始上课了,突然一天,校长的表妹的表哥家的外甥A托关系想上M中,迫于情面,校长决定接收,于是呢教务处主任根据A的分数除以36得到的余数把其分配到2班(他就考了38分嘛),突然一天,突然一天,后来又陆陆续续来了不少关系户,现在的每班人数基本稳定在120左右了。
同学们愉快的上课,校长和老师每天也都很开心的管理和教学。
当你索引一个文档,它被存储在单独一个主分片上。Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文 档,它是如何知道是应该存储在分片1还是分片2上的呢?
事实上,它根据一个简单的算法(和分班策略类似)决定:
shard = hash(routing) % number_of_primary_shards
routing 值是一个任意字符串,它默认是 _id 但也可以自定义。这个 routing 字符串通过哈希函数生成一个数字,然后除以
主切片的数量得到一个余数(remainder),余数的范围永远是 0 到 number_of_primary_shards - 1 ,这个数字就是特定文档所
在的分片。
这也解释了为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就 失效了,文档也就永远找不到了。
副本你就将其作为备份理解就行了,比较容易。
主分片和复制分片如何交互呢?
假设有三个节点的集群,它包含一个索引并拥有两个主分片,每个主分片有两个复制分 片,它的集群分布应该类似这样:
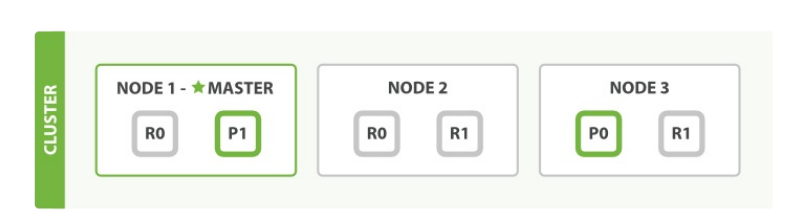
记住一点:相同的分片不会放在同一个节点上。所谓的相同指存储了同样数据的分片。
如果只有俩个节点的话,这个集群状态就是yellow, 有一份复制分片没有分配。
我们能够发送请求给集群中任意一个节点。每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也 可以将请求转发到需要的节点。简单点说:集群中的所有节点都是平等的。
当我们发送请求,最好的做法是循环通过所有节点请求,这样可以平衡负载。
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。

- 客户端给
Node 1发送新建、索引或删除请求。 - 节点使用文档的
_id确定文档属于分片 0 。它转发请求到Node 3,分片 0 位于这个节点上。 Node 3在主分片上执行请求,如果成功,它转发请求到相应的位于Node 1和Node 2的复制节点上。当所有的复制节点 报告成功,Node 3报告成功到请求的节点,请求的节点再报告给客户端。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。你的修改生效了。
不要觉得步骤繁琐,你要相信ES性能足够满足你的需要。
文档能够从主分片或任意一个复制分片被检索。
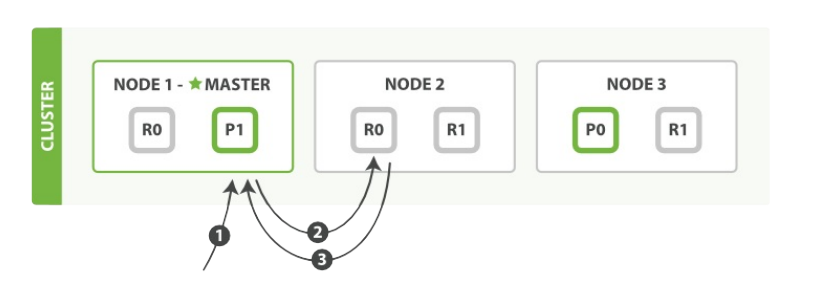
- 客户端给
Node 1发送get请求。 - 节点使用文档的
_id确定文档属于分片 0 。分片 0 对应的复制分片在三个节点上都有。此时,它转发请求到Node 2。 Node 2返回给Node 1然后返回给客户端。
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本。
下面会说到查询扩展,原理就在这,任何一个分片(不分主副)都可以用来查询。
横向扩展
随着业务的不断扩张,数据也不断增长,我们如果扩展ES呢?使用ES,我们可以很方便的进行横向扩展。
还拿上面的M中学来说,如果这个学校只有36个教室,明年的生源计划有48个班,每班撑死只能装下120个学生。校领导非常重视孩子的教育问题,马上向市国土资源局申请了一块地,建了一所分校,明年计划在老校区开设24个班,新校区开设24个班。
上面的例子就是横向扩展。
例如原来有一个索引三个分片,一套副本,两个节点。

现在增加了一个节点:
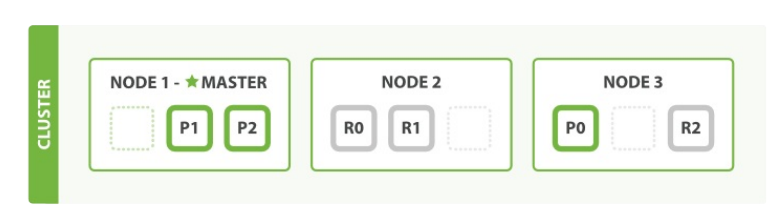
注意:由于索引的主分片是固定的,横向扩展增容能力也是有上限的,三个分片,我们最多让每个分片占据一个节点,能够存储数据的最大值取决于三个节点的存储之和,不过我们可以纵向扩展。
纵向扩展
上面横向扩展遇到了瓶颈,我们还可以纵向扩展,这个很好理解,我们花钱买更好,更大的机器即可。
由于ES天生就具有容灾能力,删除一个节点,再接入一个更好性能的机器即可,它会自动平衡数据。
切记要一个一个替换,不要一刀切。
查询扩展
之前的文章我们也介绍过,虽说主分片的数量是固定不可变的,但是我们可以更改复制分片的数量,最大存储不能增加,增加复制分片有什么用呢?
用处是有的,至少容灾能力更强这个优势还是很容易知道的。
另外,读请求——搜索和文档检索——能够通过主分片或者复制分片处理,所以数据的冗余越多,我们能处理的搜索吞吐量就越大。
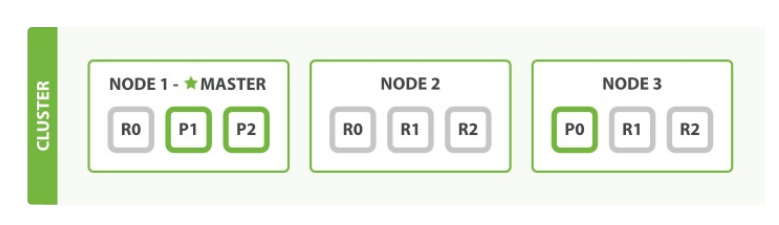
索引现在有9个分片:三个主分片和6个复制分片。这意味着我们最多能够扩展到9个节点,再次的变成每个节点一个分片。这样使我们的搜索性能相比标准的三节点集群扩展三倍。
当然,只是有更多的复制分片在同样数量的节点上并不能提高我们的性能,你需要增加硬件来提高吞吐量。
应对故障
Elasticsearch可以应对节点失效。对于3个节点,3个主分片,6个副分片的一个索引,如果我们杀掉第一个节点。
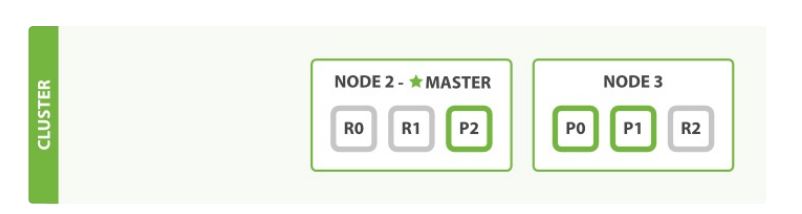
我们杀掉的节点是一个主节点。必须有一个主节点来让集群的功能可用,所以发生的第一件事就是各节点选举了一个新的主 节点: Node 2 。
主分片 1 和 2 在我们杀掉 Node 1 时已经丢失,我们的索引在丢失主节点时不能正常工作。如果此时我们检查集群健康,我 们将看到状态 red :不是所有主节点都可用!
幸运的是丢失的两个主分片的完整拷贝在其他节点上还存在,所以新主节点的第一件事是提升这些在 Node 2 和 Node 3 上的 分片的副本为主分片,集群健康回到 yellow 状态。这个提升是瞬间完成的,就好像按了一下开关。
为什么集群健康状态是 yellow 而不是 green ?我们有三个主分片,但是我们指定了每个主分片对应两个复制分片,当前却只 有一个被定义。这阻止我们达到 green 状态,不过不用太担心这个:当我们杀掉 Node 2 ,我们的程序依旧可以在没有丢失数 据的情况下运行,因为 Node 3 还有每个分片的拷贝。
如果我们重启 Node 1 ,集群将能够分配丢失的复制分片,结果状态与三主节点双复制一致。如果 Node 1 依旧有旧节点的拷 贝,它将会尝试再利用它们,它只会复制在故障期间数据变更的部分。
别名
我们知道索引在创建的时候主分片的数据就已经确定了,对于数据持续增长,当你发现原来建立的分片不够用了,并且横向和纵向都无法扩展时,别名应该被利用起来,一个好的习惯是我们应该给每个索引都创建一个别名。
别名就像人的外号一样,一个人有多个外号,不同的人可以有相同的外号。
别名带给我们极大的灵活性,允许我们做到:
- 在一个运行的集群上无缝的从一个索引切换到另一个
- 给多个索引分类(例如, last_three_months )
有两种管理别名的途径: _alias 用于单个操作, _aliases 用于原子化多个操作。
我们假设你的应用采用一个叫 my_index 的索引。而事实上, my_index 是一个指向当前真实索引的别名。真实
的索引名将包含一个版本号: my_index_v1 , my_index_v2 等等。
开始,我们创建一个索引 my_index_v1 ,然后将别名 my_index 指向它:
创建索引 my_index_v1
PUT /my_index_v1
将别名 my_index 指向 my_index_v1
PUT /my_index_v1/_alias/my_index
你可以检测这个别名指向哪个索引
GET /*/_alias/my_index
或哪些别名指向这个索引
GET /my_index_v1/_alias/*
两者都将返回下列值
{
"my_index_v1" : {
"aliases" : {
"my_index" : { }
}
}
}
然后,我们决定修改索引中一个字段的映射。当然我们不能修改现存的映射,我们需要重新索引数据。首先,我们创建
有新的映射的索引 my_index_v2 。
PUT /my_index_v2
{
"mappings": {
"my_type": {
"properties": {
"tags": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
然后我们从将数据从 my_index_v1 迁移到 my_index_v2, 一旦我们认为数据已经被正确的索引了,我们就将别名指向新的索引。
别名可以指向多个索引,所以我们需要在新索引中添加别名的同时从旧索引中删除它。这个操作需要原子化,所以我们需要
用 _aliases 操作:
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index_v1", "alias": "my_index" }},
{ "add": { "index": "my_index_v2", "alias": "my_index" }}
]
}
这样,你的应用就从旧索引迁移到了新的。
索引的数据我将其分为两类:
- 不变索引, 数据只会新增,不会被更改,如日志,聊天记录。
- 可变索引, 数据会更新,如用户资料。
对于不变索引,ES可以非常容易的扩容,只需在同一个别名下增加新的索引即可,旧数据完全不需要迁移(除非需要重新定义字段映射关系),ES支持从多个索引中查询数据。
对于可变索引,因为数据会有重叠,所以不能单纯增加索引数来解决,可变索引只能使用一份索引,最多增加主分片的数量达到扩展的目的,不过从另一个角度来说:可变索引的数量级是可预测的,比如用户信息,用户数肯定是有限的,换句话说就是不需考虑切换索引。
如果真的需要切换,我提供如下参考意见:
- 停应用,切断数据来源,重构索引,简单粗暴。
- 数据来源(主要是新增,变更和删除)进入缓冲队列,如将这些事件暂存至MQ中,阻止变更索引,等索引重构完毕,接入新的索引处理缓冲的事件。
- 将可变转换为不可变,每次变更都将当前最新的数据保存一份,历史数据不做变更,查询的时候做业务上的去重过滤处理。
本文主要介绍了集群的扩展,容灾相关的内容,有不恰当的地方欢迎留言交流。
本次的分享到此结束,希望对你有所帮助。
如果你对我分享的内容感兴趣,欢迎扫码关注公众号:新质程序猿,并设置星标,推送更实时哟!
